情報源: 日本人にだけ読めないフォント「エレクトロハーモニクス」をプログラム用エディターに設定してみたら
これも脳のパターン認識を教えてくれる。点が3つあるだけで顔に見えるのと一緒だ。
日本語OCRはこれをどう解釈するのか試してみた。
・認識結果 1
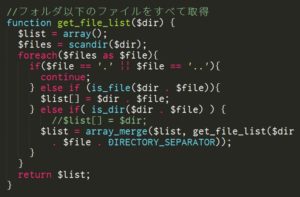
〃フォルタ以下のファイルをすべて取得
functionget_file_tist($dir){
$Ust=array();
$fites=scandir($dir);
foreach($fitesas$fite){
if($fite=='.tlI$fite=='..'){
cont工nue;
}etself(is-fite($dir.$fiLe)){
$しist[]一$dir.$fite;
}eLseif(is_dir($dir.$fiLe)){
//$List[]=$dir;
$tist=array_merge($tist,get_fiLe_tist($dir
.$fite.DIRECTORY_SEPARATOR));
}
}
return$List;
}
解像度の低い元ファイルをjpegで保存して認識したので通常のフォントのものでもミスはあるが、大半は正しく認識されている。
・認識結果 2エレクトロハーモニクス
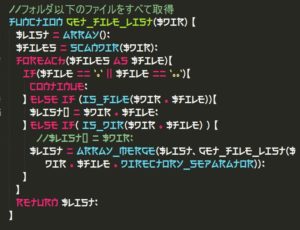
ノノフオルダ以下のファイルをすべて取得
子]白〔ナエロ白qモナ_予工レモ_レエ5ナ(事ワエR}【
事レェ5ナ=ム1《1くムγOこ
事子工レES=5こムロワエR(事ワエR);
チロRE[b(eFエレES5,子工レE)【
工子($子工レE■=㌔gl5子工レモ==㌔●')【
⊂口自ナ工口]{∋星
】モレEEエチ(工S_子工レモ…(,ワエR。,子工レ妊))【
,レエ5ナ日_,ワエ1《事予工レモこ
】モレSE子⊂工5_ワエR($ワエ1《。S子工レモ})【
ノノ事レエ5ナロ=盲ワエ1聖
,レエ5ナニムRRムソP口ERqモ(,レエ5ナ、geナ子工レ壱レエ5ナ(!ト
ワエR。,十工レE。ワエRモ[ナロRソ_5モアムKムナロR)):
】
】
尺モナコRrコ,レエSナ;
]
記号や特定の文字だけが正しく認識されている。自分と同様にカタカナとして認識しているものと漢字として認識されているのも面白い。人間だと、周囲がカタカナだと引っ張られてカタカナを優先するらしい。
上と下とを見比べて気づいたが、何箇所か自然に読める文字列がある。”List”, “if”, “else if”, “continue”, “file”, “return”, “dir”,”get” などは自然に頭に入ってくる。引用先の記事にある一番上のグラフィックの文字列はカタカナとしてしか認識できないのに。これも人間の認識を伺わせてくれる。
人間は文字列を見たときに文字列として認識しようとした後で個々の文字認識を行うのだろう。だから、「サンプンリグ」や「サソプリング」を「サンプリング」と読む。読んでしまうために校正ミスが起こるのだが、文字列で一括処理したほうが楽で速いから。FEPの文節変換と単漢字変換の差といっていいかもしれない。
そして、文字列の見かけだけでなく文脈も使って認識を進めるに違いない。